 Discover
Discover Help Centre
Help Centre Status
Status Company
Company Careers
Careers Press
PressLuno Engineering: MySQL query analysis in Go
Over the past months, the number of transactions and traffic processed by Luno has skyrocketed. Keeping pace with this growth has required the engineering team to scale and optimise the performance of all our systems.

In this blog post, we’ll describe a tool we developed to investigate and optimise our MySQL database queries that has played a major role in this effort so far.
Design considerations
At Luno, we use a microservice architecture. All our services are written in Go and our primary database is MySQL. Unfortunately, MySQL server doesn’t provide much in the way of fine-grained query-level statistics. To gain better visibility into our database queries, we opted to develop a client-side solution: a wrapper around the Go MySQL driver that intercepts all the queries and records various metrics. It can be easily dropped into existing code that uses the Go database/sql package for database access without any modification.
Prometheus metrics
We use Prometheus extensively for monitoring our systems at Luno (read more here). The database wrapper exports a Prometheus counter to measure the query rates, a histogram to measure query latency, and a counter for new connections. The metrics are reported separately for reads (selects) and writes (insert, update, delete).
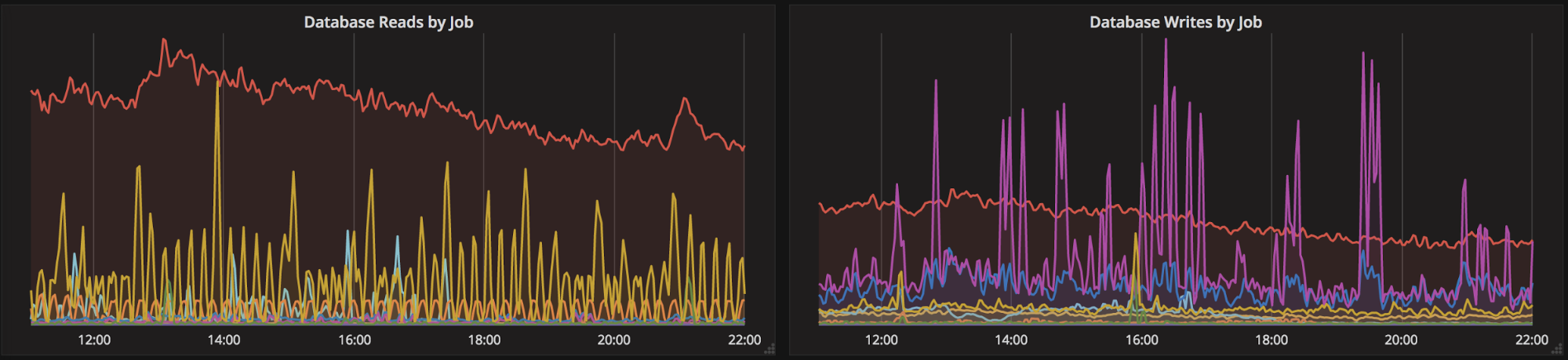
The connection rate metric helped us to notice the bad default settings of Go’s database/sql connection pool: by default the connection pool has a maximum of zero idle connections. This means it creates a new connection for almost every query. Luckily, this can easily be fixed by calling SetMaxIdleConns.
Query profiler interface
In addition to aggregate statistics, it’s very useful to see per-query metrics. To achieve this, the database wrapper provides an HTTP handler for query profiling. All our services run a debug HTTP server which we use for live pprof profiling and other monitoring tools. The database profiler is exposed through this debug HTTP server.
Engineers can use the profiler interface to capture all live queries during a time window. While capturing is active, we count and measure the total duration of each unique query. All our queries use placeholders (i.e. “select email from users where id=?” rather than “select email from users where id=1234”) so the set of queries is bounded. Once the time window has elapsed, a report of the per-query metrics is returned.
Here is an example output:

Finding queries to optimise
When selecting queries to optimise, we first sort the profiler report by total duration. It’s usually more worthwhile to optimise a 10ms query that is executed 100 times per second, than a 100ms query that’s only run once per minute. Using this approach, we were able to identify a number of queries that were slower than expected, and even redundant queries.
Consider the example output from the query profiler shown above. You can see that the sum(balance) query is slow but infrequent, while the accounts query seems to be suspiciously run more often than the users query. If the users query happens once per API request, it may mean the API request handler is unnecessarily calling the same accounts query multiple times.
By noticing a similar situation in practice, we were able to eliminate redundant queries to reduce the number of reads by 12% and improve latency by 60%.

Conclusion
Our client-side database driver wrapper has given us better visibility into our database queries and has allowed us to prioritize optimisation projects, which have already produced significant performance improvements. We continue to use it as an important tool for our work on performance and scalability.
—
Did you find this interesting? Join the Luno engineering team. View all available openings
Did you find this useful?



